|

1、maketrans法
这种办法的原理便是导入string中的punctuation,而后利用maketrans创立起一个映射字典,均指向一空格键名。再经过str.translate()清除掉文本中的所有标点符号并替换为空格。
而后利用split()的办法,把字符根据空格来切分,这般所有的单词都会切分出来,不会显现单词和标点连在一块的状况了。
from string import punctuation as punct #引入punctuation模块,给它起个别名:punct
s="Hello! Life is short, and I like Python. Do you like it?" # 设定要替换的字符串
transtab=str.maketrans({key:" " for key in punct}) #生成映射字典,把所有标点映身为空格
s1=s.translate(transtab) # 批量映射后,把结果赋值给s1
print(s1)
表示结果如下:

maketrans切分单词
2、re.split()切分法
和第1种办法类似,咱们先导入string中的punctuation,获取标点符号的字符串,而后咱们利用re.split(‘[,.!]’,string)的切分办法,再加入一个空格。最后,再利用列表推导式来去除原结果中的空元素。
import re
from string import punctuation as punct #引入punctuation模块,给它起个别名:punct
#
s="Hello! Life is short, and I like Python. Do you like it? Do" # 设定要替换的字符串
text = re.split("[{} ]".format(punct),s)
print([i for i in text if i!=""])

用re.split()切分
结果与第1种办法同样。
3、NLTK中的word_tokenize()法
这种办法必须导入自然语方处理工具包NLTK,而后利用其中的word_tokenize这个分词工具进行分词,接着再用列表推导式去除标点符号。代码如下:
from nltk import word_tokenize
s="Hello! Life is short, and I like Python. Do you like it? Do" # 设定要替换的字符串
print([i for i in word_tokenize(s) if i.isalpha()])
最后结果展示:
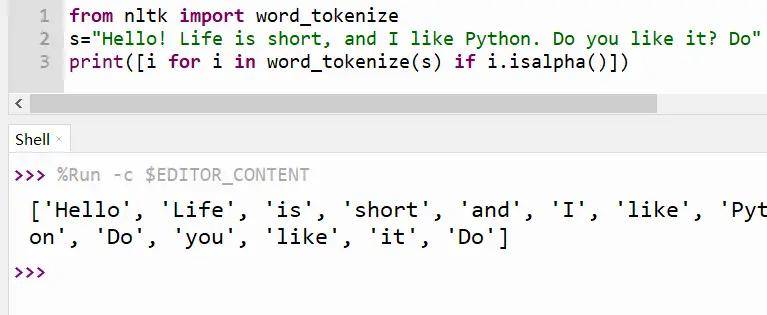
word_tokenize()切分单词
4、re. findall()法
咱们利用正则表达式模块中的findall(), 按照正则表达式【[A-z-]+】查询所有的单词,并生成这些单词的列表。最后再经过i.lower()来最小化单词。
import re
s="Hello! Life is short, and I like Python. Do you like it? Do" # 设定要替换的字符串
text = re.findall("[A-z-]+",s)
print([i.lower() for i in text])返回外链论坛:www.fok120.com,查看更加多
责任编辑:网友投稿
| 

 发表于 2024-8-16 16:31:54
发表于 2024-8-16 16:31:54



